
The Loop and the Frontier
A system that learns what 'better' means from the people who use it

This is the second in a five-part series. The first explores why AI can’t substitute for human understanding. The third shows what the epistemic loop requires when you point it at the process instead of the output.
A note on how we write: this post was developed collaboratively with AI. Our first post explains what that means and why we think the anxiety around it is misplaced.
What patterns produce. Consider a team that deploys AI agents to review code pull requests — one checking security vulnerabilities, another evaluating architectural consistency, another flagging style issues.
The agents are immediately useful but also produce noise: the security agent flags parameterized queries as SQL injection risks, the architecture agent raises concerns about formatting-only files, the style agent flags patterns in auto-generated code that nobody maintains.
The developers dismiss these findings, day after day. When a developer dismisses a finding, tools can capture that as a repo-specific rule and avoid the same false positive next time. But these rules are based on what developers did, not why they did it. They’ll be right most of the time — patterns are usually consistent. But for the findings that matter — the ones where a mistake ships a vulnerability to production — most of the time isn’t enough. If you can’t trust any individual finding without checking it yourself, the tool hasn’t added trust. It’s added volume.
What’s missing is understanding. When a developer dismisses a finding with “parameterized query, false positive,” the tool correlates that dismissal with a code pattern and produces a suppression rule. It doesn’t capture why parameterized queries are safe — that they separate user input from SQL command structure at the database engine level. The rule is a correlation. The understanding that makes it trustworthy never entered the system.
The security agent generated a plausible concern: “this looks like SQL injection.” This is abduction — inference to the best explanation from patterns in training data. The developer dismissed it with understanding — they know why parameterized queries are safe, not just that they correlate with safety. That’s evaluation grounded in genuine abstraction.
The evaluation is captured — stored as a suppression rule. But that understanding hasn’t been captured in a form that could compound. Several identical dismissals could reveal that scope is the problem — leading to narrowing that becomes durable system behavior. None of that happened automatically.
What understanding produces. When understanding accumulates rather than evaporates, the work improves with each cycle.
The developer evaluates — dismisses the finding with understanding. We’re no longer looking at a single review. Someone on the team notices the pattern across multiple evaluations — parameterized queries flagged as injection risks are dismissed every time. This is induction — reasoning from particulars to a general rule. “Humans who understand SQL injection consistently judge parameterized queries to be safe.”
The team then codifies the pattern — the security agent’s prompt is refined, or its scope is narrowed, or a stable pattern becomes a deterministic lint rule. This is where the understanding lives. In the codification itself — in its precision, its scope, its conditions. The same way business logic in software is the representation of domain understanding in an executable medium, a codification is the representation of human judgment in system behavior. The understanding didn’t get stored somewhere separate. It became the system.
From that point on, the codified rule applies to future PRs without AI involvement — if this pattern, then this action. That’s deduction. The human’s abstraction has been encoded into system behavior.
And when the codebase evolves and the codified rule starts misfiring — new evaluations contradict the pattern — the rule is falsified. The system reverts to abductive exploration, beginning the progression again.
The epistemic progression
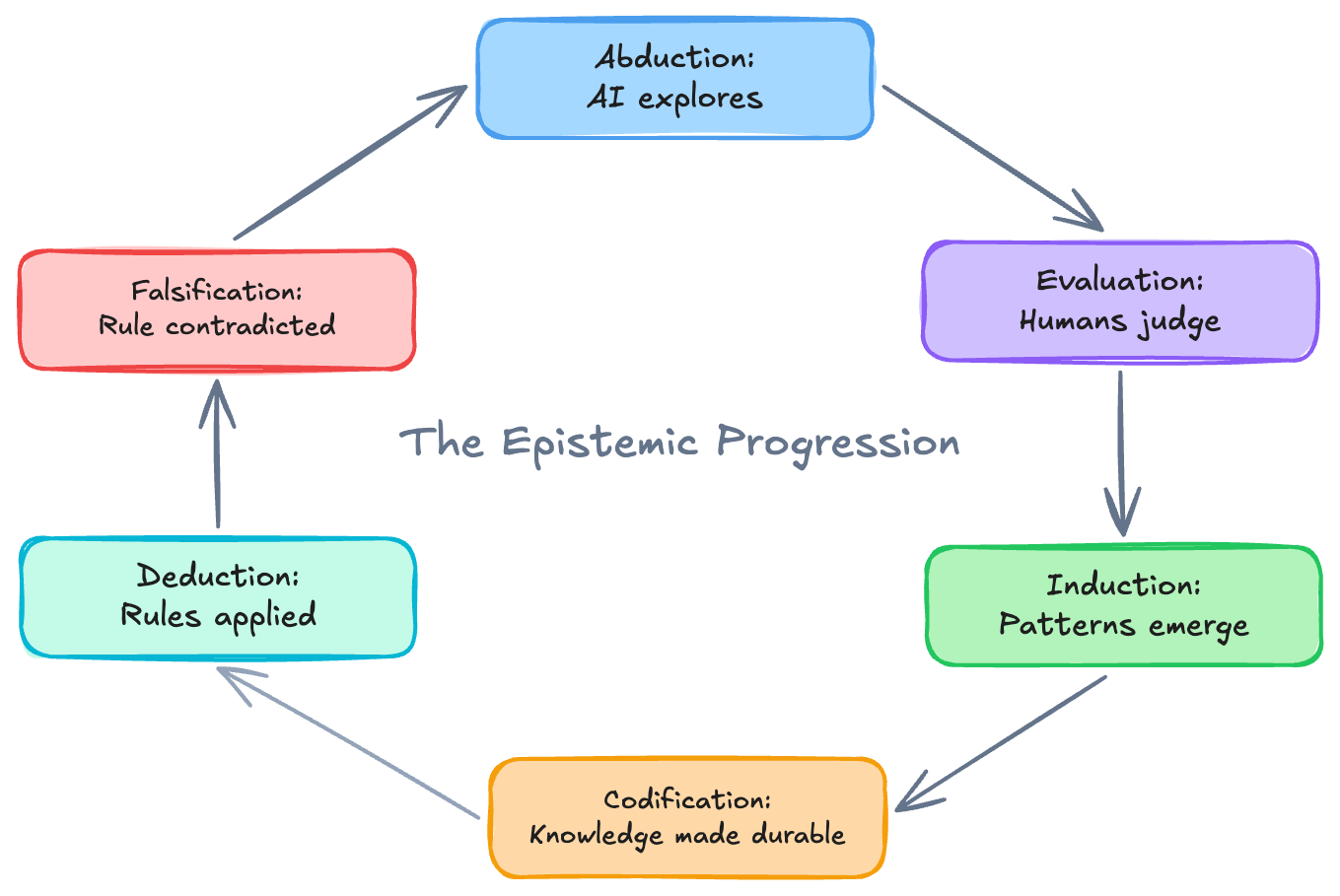
The AI explored (abduction), the human judged with understanding (evaluation), the pattern surfaced across evaluations (induction), the team approved a change to system behavior (codification), the codified rule applied deterministically (deduction), and conditions changed to invalidate it (falsification). This is the epistemic progression — and a loop.
What ultimately gets codified is why parameterized queries are safe, why the architecture agent’s concerns about formatting-only files are irrelevant, why the style agent’s findings on auto-generated code are noise. Not patterns the AI detected — the AI was the exploration engine that surfaced candidates. Not statistical correlations — those are the raw material.
Something that was previously implicit — in people’s heads, in ad hoc decisions, in tribal knowledge — becomes explicit, structured, and owned. In system behavior that reflects the accumulated understanding of the people who shaped it.
Take the human out of the loop and you’re codifying pattern matching — building deterministic rules from correlations rather than understanding. That produces exactly the brittle, confident-but-wrong systems we argued against in our first post.
Notice something about the improvements we’ve described. They all came from the same loop, yet they move the system in different directions — some purely forward, some involving tradeoffs, some opening up capabilities that didn’t exist before. The parameterized query fix removed noise without any cost — pure gain. Narrowing an agent’s scope could improve accuracy and reduce cost and increase consistency. Adding a performance review agent would improve coverage but increase cost. Crystallizing a pattern into a lint rule eliminated cost entirely for that check.
How improvement stays aligned
The loop tells us how improvement happens. It doesn’t tell us whether the improvements are moving toward what the people using the system actually value — especially when they pull in different directions.
The code review system has quality, cost, speed, coverage, and the amount of human oversight required. The Pareto frontier — a concept from multi-objective optimization — gives us a way to reason about this. It’s the boundary of what’s currently achievable across all objectives at once, given the system’s existing tools, agents, knowledge, and constraints. It’s not a theoretical limit; it’s a practical one that shifts as the system’s capabilities change. Every point on the surface represents a configuration where you can’t improve one dimension without giving something up on another. Points below the surface are inefficiencies — configurations where a change could improve one or more dimensions without hurting any.
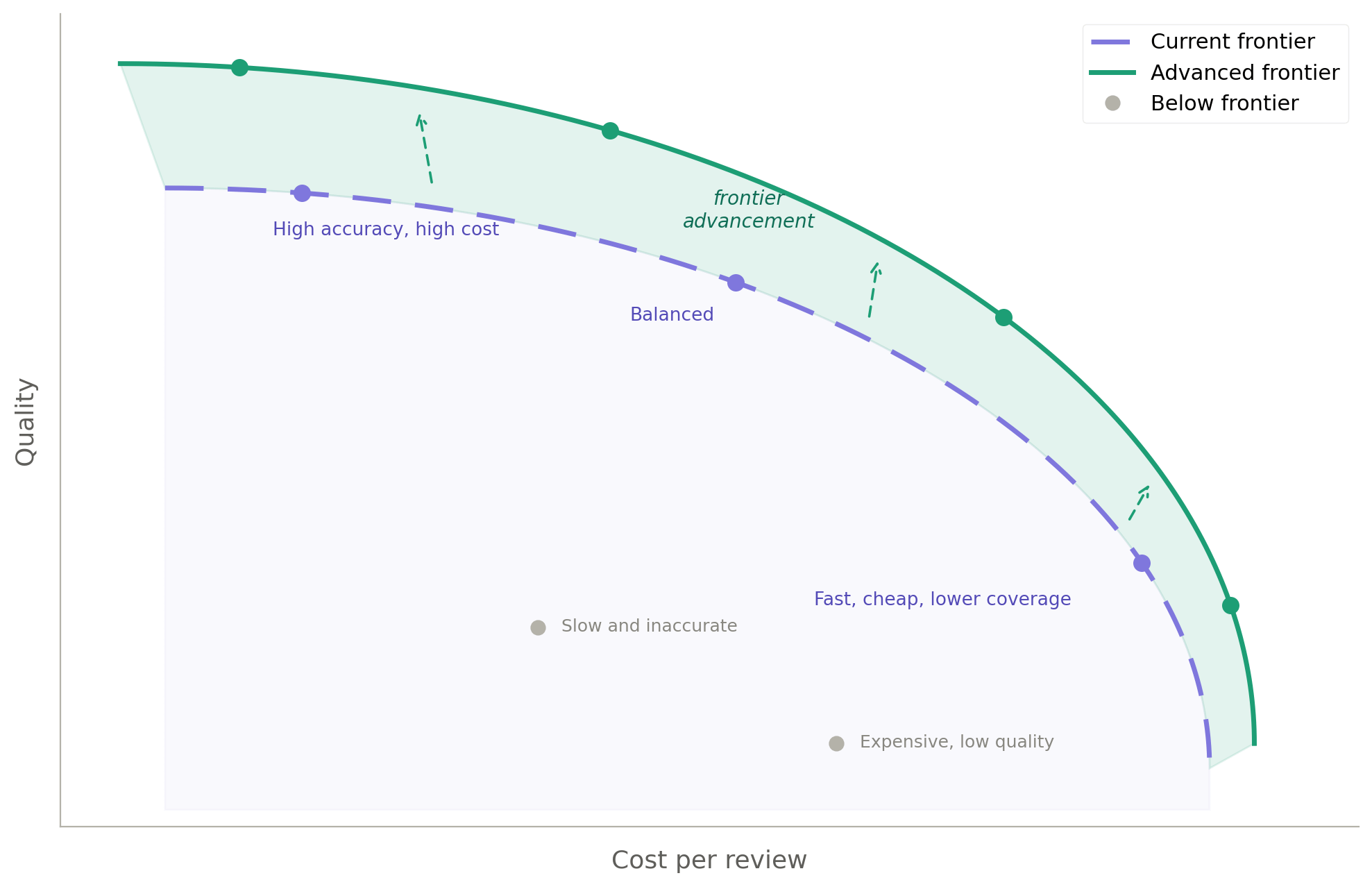
What the frontier makes visible is direction. The loop runs. Every cycle produces an outcome. But without a framework for what “better” means across dimensions, different stakeholders can improve toward different things simultaneously — and the loop, running faithfully, compounds the divergence rather than resolving it. The frontier gives human evaluation its orientation: not just whether a codification is right, but whether it’s moving the system toward what actually matters.
When a codification drifts from what a stakeholder values, their evaluations change. Developers start rejecting findings they used to accept. Dismissal rates spike after a scope change. These shifts are visible in the evaluation records the loop already produces. This is falsification applied to alignment — the same mechanism that catches bad codifications catches misalignment at the values level. And the system reverts to exploration.
Every human evaluation is a signal about whether the system is serving what they value.
How the loop moves the frontier
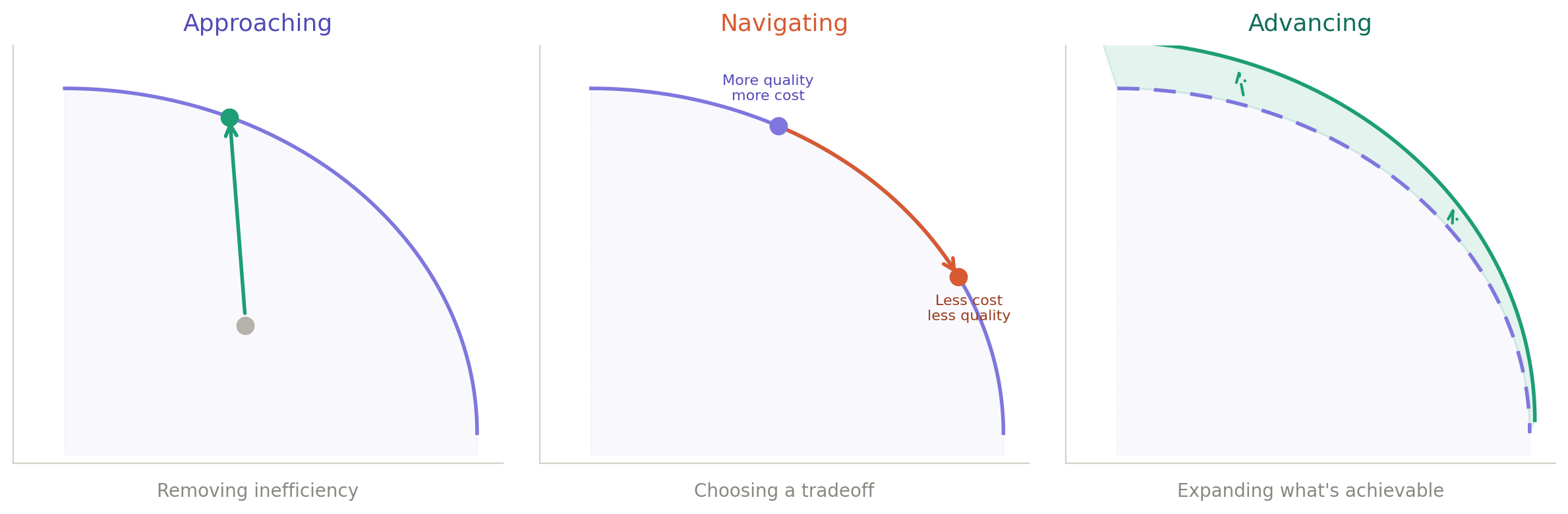
Each pass through the epistemic progression either moves the system toward the frontier, to a different position on it, or pushes the boundary outward. Not all moves are the same.
Approaching the frontier. The system is below its own frontier — an inefficiency exists. A prompt refinement that teaches the security agent about parameterized queries improves accuracy without affecting anything else. Pure gain.
Navigating the frontier. The system is already on the frontier, and a change moves it to a different position on the existing surface. Adding the performance agent — because production incidents revealed latency regressions no existing agent caught — improves coverage but increases cost. Whether that’s an improvement depends on where the team wants to be.
Advancing the frontier. The boundary itself pushes outward. When the team discovers that entire categories of findings are consistently dismissed — the security agent never surfaces useful findings from CSS files, the style agent’s findings on auto-generated code are dismissed every time — and narrows each agent’s scope accordingly, something striking happens. Quality, cost, consistency, and auditability all improve simultaneously. No tradeoff. The boundary of what’s achievable expanded outward.
When a stable pattern crystallizes into a deterministic rule — the style agent’s auto-generated code finding, flagged and dismissed 50 straight times, becomes a lint rule — cost goes to zero, speed goes to instant, reliability goes to perfect. AI eliminated itself from that check. When conditions change and the rule starts misfiring, the system reverts to abductive exploration. The frontier is always the current state of what’s achievable.
Where this leads
The loop ran on the work — agents explored, humans evaluated, understanding became durable system behavior. It also ran on the process of working — humans noticed patterns across those evaluations and proposed changes to how the review happens, which agents run, what gets captured. At both, human attention drove the loop — and at both, those same human evaluations were what kept improvement aligned. The evaluation step that drives the loop is the alignment mechanism — the loop and the frontier are the same thing seen from different angles.
Now ask: could the process of working itself be improved through the same loop? Could it get better at detecting patterns — learn from which proposals the team accepted, notice which kinds of improvements it keeps missing, and refine its own approach?
Yes. The loop applies to the process of working just as it applies to the work. The frontier applies there too. The structure is the same.
But making it practical at each level requires rebuilding from scratch. The work produces code review findings — violations caught, rules applied, decisions made. The process of working produces a different kind of record — evaluations made, proposals accepted or rejected, patterns noticed across sessions. The process of improving the process of working produces yet another — which proposals succeeded, which failed, and why. Each level produces differently shaped records, and so requires its own tools, its own queries, built anew.
Beyond two or three levels, it becomes hard to even think about — the mind can’t hold that many distinct systems at once.
If the loop worked at every level without this overhead, the improvements would compound. Each cycle would make the next one faster, cheaper, better targeted. You wouldn’t just be building things better — you’d be getting better at building things with each project you ship.
What would it take to make that compounding real — to make improvement and alignment at every level as practical as at the first? To make the improvement process itself something that doesn’t have to be redesigned each time. To let the returns actually accelerate.
That’s next.