
The Forge

This is the third in a five-part series. The first explores why AI can’t substitute for human understanding. The second shows how understanding becomes durable system behavior and improvement stays aligned.
A note on how we write: this post was developed collaboratively with AI. Our first post explains what that means and why we think the anxiety around it is misplaced.
Our second post showed the epistemic loop running on work — AI exploring, humans evaluating, understanding becoming durable system behavior. It closed with a question: what would it take to make that compounding real at every level — not just on the work itself, but on the process of doing the work?
This post is about the second half of that question — what the loop produces when you point it at the process of doing the work rather than the work itself.
The loop on the work
We started building serious software with Claude about a year ago.
We’d describe what we wanted and Claude would produce a working version in minutes. Not always the right version. But a starting point we could evaluate, correct, and refine faster than we could have written from scratch. The exploration phase of development — trying approaches, seeing what breaks, iterating toward the right design — compressed from days to hours.
Here’s a typical exchange. We need a request handler. Claude generates:
async function handleRequest(req: any, services: any): Promise<any> {
const parsed = JSON.parse(req.body);
const result = await services.process(parsed);
return { status: 200, data: result };
}It works. But every any is a place where the compiler can’t help, where a refactor will silently break callers, where the next developer has to read the implementation to understand the contract. We know why this isn’t good enough — not because the code fails now, but because we understand how this codebase will evolve. any tells the compiler to stop checking. A function that accepts any will silently accept the wrong arguments, return the wrong shape, break its callers — and none of it will surface until the software is in production, long after the mistake was made. So we correct it:
interface ProcessRequest {
userId: string;
action: 'create' | 'update' | 'delete';
payload: Record<string, unknown>;
}
async function handleRequest(
req: ValidatedRequest<ProcessRequest>,
services: ServiceContainer
): Promise<ApiResponse<ProcessResult>> {
const result = await services.process(req.body);
return { status: 200, data: result };
}Every named type is understanding encoded as structure. ValidatedRequest means the body is parsed and validated before the handler sees it. The union type rejects invalid actions at compile time. These aren’t just better types — they’re decisions made because we understood something the AI didn’t about how this system will be maintained. We knew this handler would be called from contexts that didn’t exist yet. We knew other developers would read it as a contract, not an implementation detail. Years of watching implicit assumptions become production bugs — that’s where the correction came from, not from reading the code.
The AI has no way to know what we know — and not all of what we know is obvious. It’s not just how this codebase will evolve. It’s the patterns that take years to pick up: what any costs when a codebase grows, what happens to undocumented contracts across a refactor. A junior engineer might spot the problem and still not know why it matters. Every correction is that experience entering the loop. The corrections add up. The types get stricter, the abstractions sharpen, the architecture firms up. Each pass makes the next pass more productive.
This is the epistemic loop, running on real software.
The loop on the process
The code bugs get fixed. Each any we correct, each missing validation we add — these are problems in the output. We fix them, the code improves, we move on.
But a different kind of problem surfaces. Not in the code — in the process. Patterns in Claude’s behavior that repeat across sessions, independent of what we’re building.
Claude keeps using any types unless we catch it. It keeps writing comments that describe what the code used to do — // Refactored from the old validation system — instead of what it does now. It treats test coverage as optional. Recurring process failures — and we’re the ones abstracting over many sessions to identify them.
The loop is running one level up. Instead of evaluating Claude’s code and codifying understanding into types, we’re evaluating Claude’s behavior and trying to codify understanding into process rules.
So we start writing down what we’ve learned. A CLAUDE.md file grows:
- YOU MUST NEVER add comments that reference what used to be there
- NEVER add `any` types unless explicitly approved
- ALL new features MUST have comprehensive test coverage
- Tests MUST test real logic, NOT mocked behavior
- Test output MUST BE PRISTINEBehind each rule is a story. MUST test real logic, NOT mocked behavior — that’s the session where Claude wrote a test that verified its own mock returned the expected value. Test output MUST BE PRISTINE — that’s the session where warning messages masked a real failure that went unnoticed for two days. They’re scar tissue that teaches.
Then we watch Claude ignore a rule we wrote two hours ago.
Not maliciously. Not because the rule was ambiguous. Claude read it, acknowledged it, and three tasks later — deep in a complex refactor — wrote // Moved from the old validation module. The rule says don’t do this. We correct it, it apologises, and the next file starts with // Refactored from the previous approach. Adding emphasis, examples, and rationale pushed the violation rate down, but never to zero.
The AI generates output by weighting what’s statistically likely given its training data. An instruction marked NEVER shifts those weights — but the model has no way to know why temporal markers degrade a codebase. It only knows it’s been told not to write them.
A partial answer
We needed a way to enforce rules — enforcement the AI could not ignore.
Claude Code has a hook system — scripts that run automatically when session events occur. Write a file, an event fires. Finish a task, an event fires. Any code you register against that event runs.
Register a script against the file-write event and it can scan every file Claude touches for temporal markers. Register a script against the task-complete event and it becomes a gate: if violations exist, Claude can’t finish until they’re resolved. And it works, to a point. A regex for // Refactored from either matches or it doesn’t. A stop gate either blocks or allows. Deterministic where the AI is probabilistic.
But each script fixed one thing. The next problem would need another. There was no version of this that ended. There was something deeply uncomfortable about spending time writing compensatory code around a system that was supposed to be intelligent — patching individual behaviours by hand when the goal was to build real products, not to babysit an LLM.
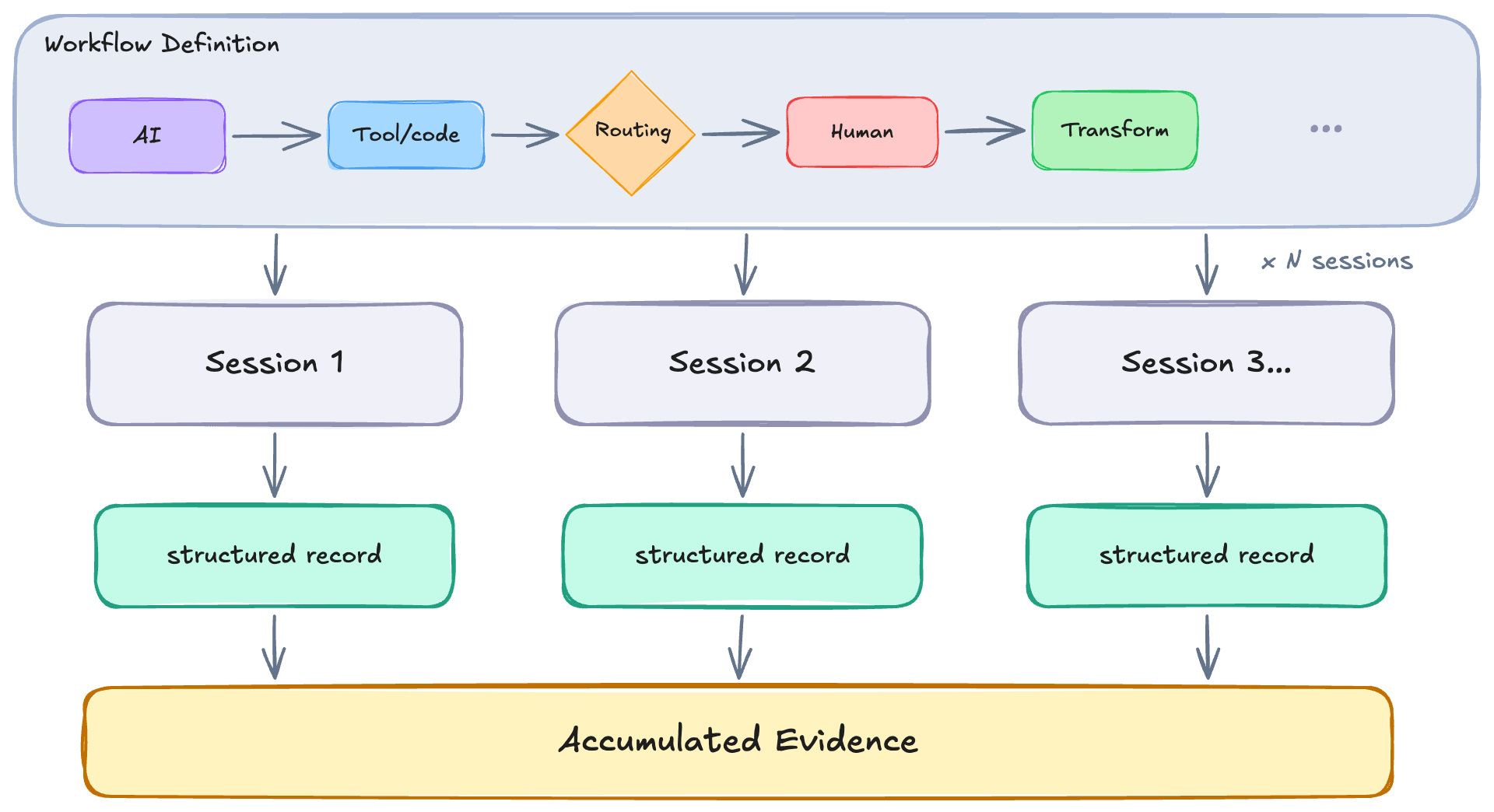
What we came up with instead was a framework that safeguarded and corralled Claude’s output systematically — accumulating evidence across sessions while keeping the cost of a new rule near zero. Maintaining alignment became something that compounded rather than reset with each session.
The form this took was a workflow — a definition that expressed the rules separately from the machinery that ran them. Adding a check, adjusting a condition, composing multiple rules together: any of it costs almost nothing, because the orchestration itself is generic and never needs to change. A structured record accumulates as a natural consequence — something to reason over rather than side effects that evaporate when a gate fires.
Separating definition from execution
This isn’t a novel idea in software. GitHub Actions defines workflows as a sequence of steps in YAML that run on triggers. The value is the same: separate the definition from the execution, and every run becomes a structured, reproducible instance of the same process. What’s different here is what the workflow is operating on — not a CI pipeline, but the AI-assisted development process itself.
A workflow in our context is a sequence of steps for achieving some goal — deterministic checks, AI reasoning, tool calls, human decisions — expressed as a definition that a system can execute repeatedly. The definition and the execution are separate. Each execution is an instance of the same structure. We attached them to our development process — not as more instructions for Claude to weigh, but as processes that observe Claude’s output and act on it in a controlled fashion.
When Claude writes code, a workflow runs. It checks for the specific violations we’ve codified: comments that reference what used to exist, type annotations that abandon type safety, tests that verify their own mocks. Each of these checks is binary. Match or no match. No weighing, no probability.
The workflow accumulates violations across the session and holds them.
When Claude is ready to stop — when it thinks the work is done — a different workflow runs:
> Unresolved violations:
> - temporal_marker in handler.ts:42 — "Refactored from old system"
> - any_type in services/processor.ts:17 — Unapproved `any` in ProcessorConfig
>
> Fix these before completing the task.Claude is blocked. The rule that was ignored as an instruction is enforced as a gate. The same understanding, encoded differently — not as text the AI weighs against everything else, but as a process that runs on the AI’s output and acts on it regardless.
What we discovered
Running these guardrails helped immensely, but also revealed something we hadn’t anticipated.
Because each step in a workflow is a discrete operation with recorded inputs and outputs, everything the process does is observable — not as a monolith, but as structured, queryable evidence. The evaluation step no longer evaporates. It accumulates, and the loop has something genuinely new to run on: not just this instance of a problem, but the pattern across hundreds of instances.
When the mechanism causes friction — when we notice, three sessions in, that test failures are being diagnosed by re-running the full suite just to see more output, or that ‘revert this change’ keeps discarding unrelated work — and the frustration in our language shifts — that friction is a signal. Evidence that there’s a pattern the guardrails haven’t learned to see yet.
So we built a different workflow that captures this: when a session shows signs of repeated friction, it records the full context — what we were building, what Claude just did, what triggered the frustration — analyzes the pattern, and creates a structured record.
After many sessions, these instances accumulate into a structured, growing record. And because the system has a language for expressing what to do with it, the next step — running the loop on the loop itself — is not a new engineering project. It is just another workflow.
What that produces is what the next post is about.